파이썬 beautifulsoup select 사용법에 대해서 알아보겠다. 여러 번 사용해봐야 개념을 알 수 있고, 직접 코드를 작성하는 것이 최고라고 생각한다.
beautifulsoup을 이용해 웹 스크래핑을 할 때 중요한 것은 내가 원하는 정보를 잘 정제해서 가져오는 것이다. 그냥 무턱대고 모든 HTML 코드를 가져오면, 해석하기도 힘들고, 큰 의미가 없다.
파이썬(Python) beautifulsoup에서는 select를 이용해 내가 원하는 정보를 손쉽게 가져올 수 있다. 이번 시간 select를 사용해 네이버 랭킹 뉴스 크롤링(사실 웹 스크래핑이 맞는 말이라고 한다.)을 해보겠다.
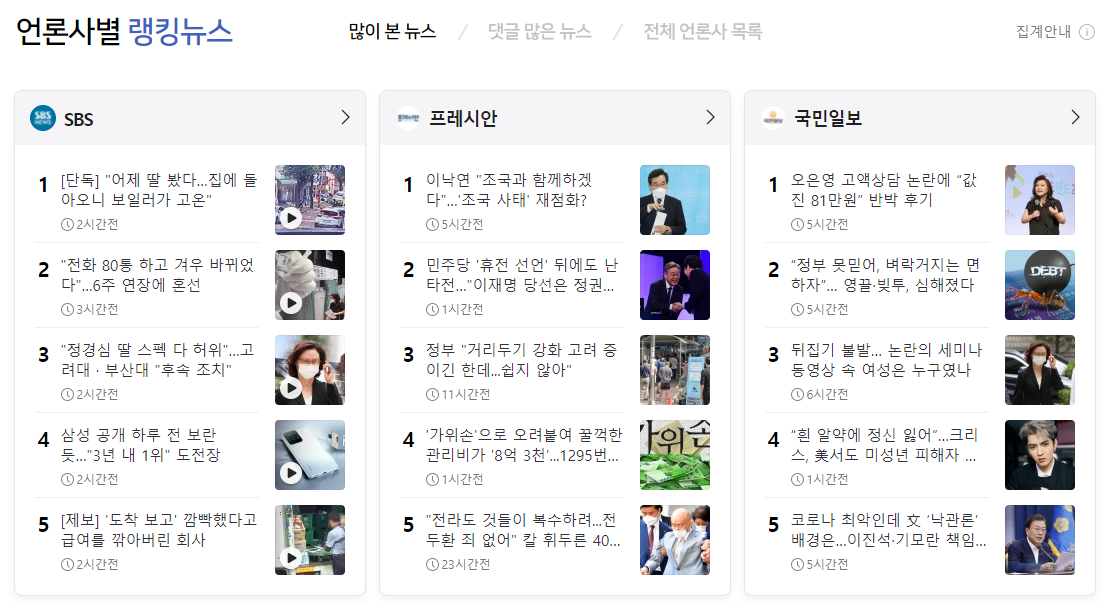
★ 목표 : 네이버 뉴스 - 언론사 별 랭킹 뉴스 제목 가져오기!
참고 : 언론사별 랭킹 뉴스는 일정시간이 지나면 새로고침이 된다. 새로고침이 되면, 순서가 바뀔 수 있으므로 결과값이 달라진다고 해서 이상해 할 필요 없다.

전체적인 구조를 확인해본 결과 rankingnews_box가 여러 개 존재하며, 그 안에 우리가 원하는 제목들이 들어있다.
- 접근 방식 : 첫 번째 'rankingnews_box'(SBS)에 접근한 후, 1~5위 제목 값을 가져온다. 두 번째 'rankingnews_box'(프레시안)로 넘어간 후 1~5위 제목 값을 가져온다. ··· (반복)
즉, 반복문을 두 번 사용해야 한다. 예시를 조금 어려운 것으로 한 것 같은데, 코드를 모두 작성해 놓고 보면, 생각보다 어렵지 않다.
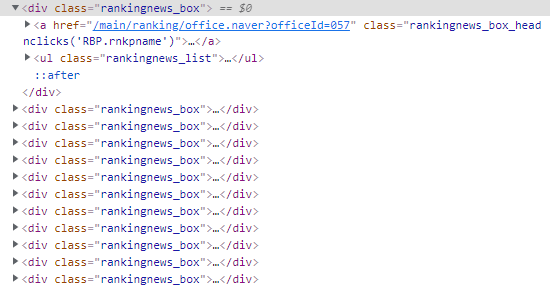
HTML 코드를 확인해보면, rankingnews_box가 여러 개 존재하며, 그 안에 1~5위 제목이 들어있다.

빨간색 네모로 표시된 부분에 우리가 원하는 정보가 모두 담겨있으므로 가져오겠다. 코드는 다음과 같다.
from bs4 import BeautifulSoup
import requests
URL = 'https://news.naver.com/main/ranking/popularDay.naver'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(URL, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
rankingnews_boxs = soup.select('#wrap > div.rankingnews._popularWelBase._persist > div.rankingnews_box_wrap._popularRanking > div > div')
beautifulsoup select는 find_all과 비슷한 역할을 한다. 위 코드를 설명하자면, rankingnews_boxs 변수에 <div class=rankingnews_box>인 태그를 모두 가져오겠다는 뜻이다.
for rankingnews_box in rankingnews_boxs:
rankingnews_lists = rankingnews_box.select('ul > li')
rankingnews_name = rankingnews_box.select_one('a > strong').text
print('rankingnews_name :', rankingnews_name)
for rankingnews_list in rankingnews_lists:
rank = rankingnews_list.select_one('em').text
title = rankingnews_list.select_one('div > a').text
print(rank, '위 : ', title)for문을 이용해 rankingnews_boxs를 하나씩 탐색한다.
rankingnews_name은 어떤 언론사인지 파악할 수 있는 값이 들어간다.

- rankingnews_lists > em : 몇 순위인지에 대한 정보가 들어있다.
- rankingnews_lists > div > a : 뉴스 기사 제목 정보가 들어있다.
예를 들어, <a>태그 안에 있는 텍스트 값을 가져오고 싶다면, select_one('~~').text를 이용하면 된다.

select를 이용해 목표하는 값의 무리들을 가져오고, select_one을 통해 하나씩 접근한다고 생각하면 된다. select를 이용하면, 반복문은 거의 따라온다고 봐도 무방하다. 왜냐하면, 여러 개의 값을 가져왔으니, 하나씩 확인을 하기 위해서는 하나씩 체크하면서 넘어가야 하기 때문이다.

그러니까 select를 이용해 파란색 부분을 가져오고(물론 그 이상의 데이터도 포함되어 있지만), select_one을 이용해 빨간색 부분 그러니까 내가 원하는 값을 가져오면 된다.
첫 번째(연합뉴스)가 끝이 아니므로 반복문을 통해 다음 번째(중앙일보)로 넘어가서 똑같은 작업을 수행하는 식이다. 반복문을 두 번 사용해야 하는 예시를 들고 와 헷갈릴 수 있지만, 코드를 자세히 보면, 그렇게 복잡한 구조는 아니다.
[Python] 웹크롤링 이미지 저장 - 쿠팡 상품 이미지 긁어오기
네이버 블로그를 이용해 쿠팡 파트너스를 할 때 꼭 이미지를 넣어야 하는 것은 아니지만 이미지가 있고 없고의 차이는 크다. 이왕이면 넣는 것이 좋다. 사람들이 글자보다는 이미지를 인식하는
kissi-pro.tistory.com
[Python] 네이버웹툰 크롤링 - 제목, 링크주소 가져오기
파이썬 'BeautifulSoup'을 이용하면 다양한 정보를 얻어 올 수 있다는 것은 이전 시간에 네이버 블로그 글 제목과 링크, 본문을 가져오는 실습을 해보면서 알았다. 이번 시간에는 현재 업로드 중인 '
kissi-pro.tistory.com
[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1
뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후 나온 결과의 네이버 블로그 제목과 URL을 가져올 예정이다. import requests from bs4 import BeautifulSoup from urllib.parse import quote query = "s..
kissi-pro.tistory.com
'Information' 카테고리의 다른 글
| 칼리리눅스(Kali Linux) 한글깨짐 해결방법 (0) | 2021.11.13 |
|---|---|
| VMware 워크스테이션 16 다운로드 및 설치 방법 (0) | 2021.11.13 |
| [Python] 네이버 블로그 자동 포스팅 프로그램 만들기 - 3. 사진 올리기 (3) | 2021.08.09 |
| [Python] 웹크롤링 이미지 저장 - 쿠팡 상품 이미지 긁어오기 (2) | 2021.08.08 |
| [Python] 네이버 블로그 자동 포스팅 프로그램 만들기 - 2. 제목, 본문 작성 (6) | 2021.08.05 |



