목차
뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후 나온 결과의 네이버 블로그 제목과 URL을 가져올 예정이다.
import requests
from bs4 import BeautifulSoup
from urllib.parse import quote
query = "sk하이닉스"
url = "https://search.naver.com/search.naver?where=view&sm=tab_jum&query=" + quote(query)
네이버에 'sk하이닉스'라고 검색한 후 View탭으로 이동하면, 아래와 같이 URL이 나오는 것을 확인할 수 있다.

quote함수를 이용해 아스키 코드 형식이 아닌 글자를 URL인코딩 해줄 필요가 있다. 그래서 query 변수에 검색할 단어를 담고, 그 후 quote함수를 사용해 URL인코딩을 해준 것이다.
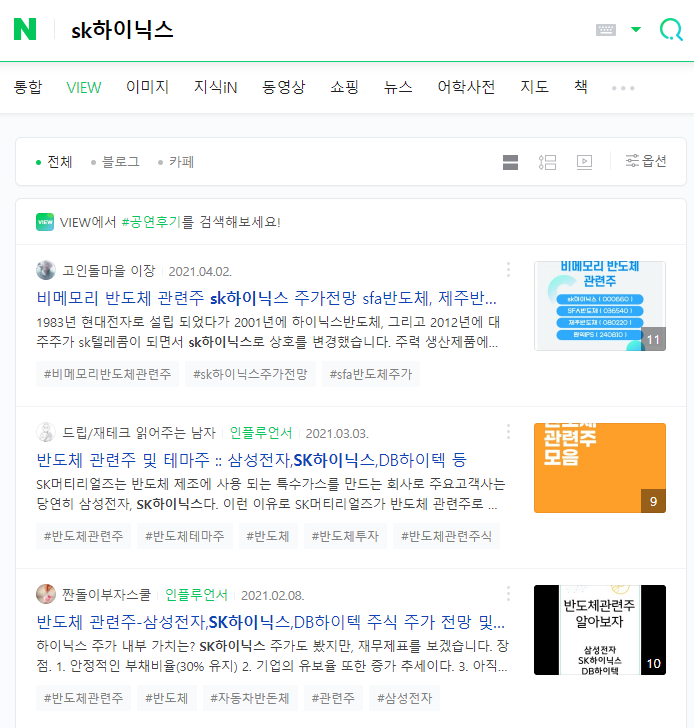
url 변수 안에는 위 링크 정보를 담고 있다. 우리가 원하는 것은 위 화면에서 제목과 링크주소이다. 이곳에서 분석을 시작하면 된다.

F12를 눌러 개발자도구를 켠 후 하나씩 확인해본 결과 <li>태그로 되어 있는 것을 확인할 수 있다. BeautifulSoup의 find_all()을 이용해 <li>태그를 모두 가져올 예정이다. 코드는 다음과 같다.
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 문제시 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
posts = soup.find_all("li", attrs={"class":"bx _svp_item"})
posts 변수에 class가 'bx _svp_item'인 <li>태그를 모두 가져왔다. 이제 반복문을 통해 하나씩 보면서 내가 원하는 정보만 얻으면 된다.

우리가 원하는 제목, 링크 주소 정보는 모두 <li>태그 안에 있는 class명이 'api_txt_lines total_tit'인 <a>태그 안에 있다.
링크 주소는 <a>태그의 href 정보를 가져오면 되고, 제목은 get_text()를 이용해 텍스트만 가져오면 된다.
for post in posts:
post_title = post.find("a", attrs={"class":"api_txt_lines total_tit"}).get_text()
print("제목 :",post_title)
post_link = post.find("a", attrs={"class":"api_txt_lines total_tit"})['href']
print("link :", post_link)
print("-"*50)
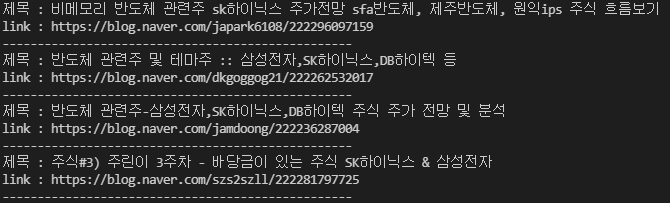
이렇게 해서 BeautifulSoup을 통해 우리가 원하는 정보를 가져올 수 있다. 링크 주소 정보가 있으니, 조금 더 가공하면, 본문도 긁어 올 수 있을 것으로 보인다.
2021.05.23 - [파이썬] - [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2
[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2
지난 시간에 BeautifulSoup을 이용해 네이버 View에 있는 정보(글 제목, URL)를 가져왔다. [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1 뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후..
kissi-pro.tistory.com
2021.05.28 - [파이썬] - [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 3
[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 3
[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1 뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후 나온 결과의 네이버 블로그 제목과 URL을 가져올 예정이다. import requests from bs4 impor..
kissi-pro.tistory.com
'Information' 카테고리의 다른 글
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 3 (0) | 2021.05.28 |
|---|---|
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2 (0) | 2021.05.23 |
| 네이버블로그 상위 랭크 10등까지 제목과 링크 가져오기 - 파이썬 웹크롤링 (2) | 2021.05.06 |
| [Python] 파이썬 문자열 대문자, 소문자로 바꾸기 (0) | 2021.04.30 |
| 티스토리 코드블럭 테마 플러그인으로 바꾸기 (0) | 2021.04.26 |



