[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1
뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후 나온 결과의 네이버 블로그 제목과 URL을 가져올 예정이다. import requests from bs4 import BeautifulSoup from urllib.parse import quote query = "s..
kissi-pro.tistory.com
[Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2
지난 시간에 BeautifulSoup을 이용해 네이버 View에 있는 정보(글 제목, URL)를 가져왔다. [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1 뷰티플수프(BeautifulSoup)를 이용해 특정 키워드 검색 후..
kissi-pro.tistory.com
네이버 블로그 본문까지 긁어오는 코드를 작성해보았다. 카페와 네이버포스트의 본문도 가져오게 하려고 했으나, 셀레니움을 사용하지 않으면 안 될 것 같아 그것은 잠시 보류하기로 했다. 우선 블로그만 목표로 잡고 코딩할 예정이다.
이전 시간에 문제되었던 점은 '스마트에디터 ONE'으로 작성된 글만 가져올 수 있었다. 네이버블로그 에디터는 현재 2가지가 존재한다.
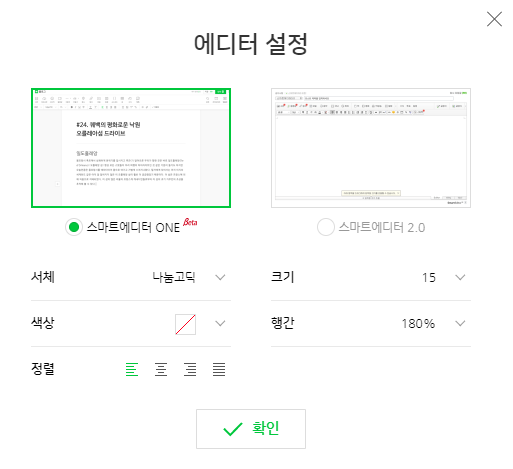
현재까지 작성한 코드는 왼쪽의 '스마트 에디터 ONE'만 긁어오며, '스마트에디터 2.0'은 본문을 가져오지 못한다. 링크와 제목은 모두 올바르게 가져온다.
에디터가 무엇인지 if문으로 구분한 후 그에 맞게 크롤링 하는 코드를 작성할 예정이다.

현재 짠 코드를 실행시켜보면, 'sk하이닉스'로 검색했을 때 위와 같이 '확인불가'메세지를 확인할 수 있다. 아래 있는 것(형광색으로 표시된 부분)은 포스트로 작성한 글이므로 '확인불가'라고 출력되는 것이 맞다. 하지만, 위에 있는 것(빨간색으로 표시된 부분)은 네이버블로그임에도 불구하고, '확인불가'메세지가 나오고 있다.
들어가서 확인해본 결과 역시나 스마트에디터 2.0으로 작성된 글이었다. 이제 이것에 대한 처리를 하도록 하겠다.

개발자도구를 이용해 확인해본 결과 에디터 2.0으로 작성한 글의 본문은 id가 'postViewArea'인 <div>태그 라는 것을 확인할 수 있었다. text_scraping 함수를 아래와 같이 수정했다.
# 네이버블로그 본문 스크래핑
def text_scraping(url):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status() # 문제시 프로그램 종료
soup = BeautifulSoup(res.text, "lxml")
if soup.find("div", attrs={"class":"se-main-container"}):
text = soup.find("div", attrs={"class":"se-main-container"}).get_text()
text = text.replace("\n","") #공백 제거
return text
elif soup.find("div", attrs={"id":"postViewArea"}):
text = soup.find("div", attrs={"id":"postViewArea"}).get_text()
text = text.replace("\n","")
return text
else:
return "네이버 블로그는 맞지만, 확인불가"
if문을 이용해 'soup.find("div", attrs={"id":"postViewArea"})'가 참일 경우, 해당 본문을 가져오도록 했다. 실행해본 결과 아까와 다르게 본문을 잘 긁어올 수 있었다.
이렇게 해서 'BeautifulSoup'을 이용해 네이버블로그 크롤링을 해보았다. find_all(), find()만 제대로 활용할 줄 알아도 원하는 데이터를 쉽게 가져올 수 있을 것이다.
전체 코드 : https://github.com/tiger-beom/naverblog_scraping.git
tiger-beom/naverblog_scraping
Naver Blog crawling, scraping. Contribute to tiger-beom/naverblog_scraping development by creating an account on GitHub.
github.com
'Information' 카테고리의 다른 글
| [Python] 쿠팡 크롤링 - 상품 제목 가져오기 (0) | 2021.06.22 |
|---|---|
| [Python] 네이버웹툰 크롤링 - 제목, 링크주소 가져오기 (0) | 2021.05.29 |
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2 (0) | 2021.05.23 |
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 1 (1) | 2021.05.23 |
| 네이버블로그 상위 랭크 10등까지 제목과 링크 가져오기 - 파이썬 웹크롤링 (2) | 2021.05.06 |



