목차
이번 시간 파이썬(Python)을 이용해 웹크롤링 해볼 사이트는 바로 '쿠팡(coupang)'사이트이다. 요즘 다양한 SNS를 통해 쿠팡파트너스 홍보를 하는 사람들이 많아졌다. 유튜브에 검색을 해보더라도 쿠팡파트너스와 관련된 영상이 참으로 많이 나온다.

'쿠팡 홈페이지 - 로켓배송'을 눌렀을 때 나오는 상품제목(상품명)을 가져오려고 한다.
import requests
from bs4 import BeautifulSoup
import re
URL = 'https://www.coupang.com/np/campaigns/82'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(URL, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")BeautifulSoup을 이용해 URL 변수에 들어있는 주소의 정보를 가져오는 코드다. 이전에 네이버블로그 스크래핑 했을 때의 앞부분과 크게 다를 것이 없다.
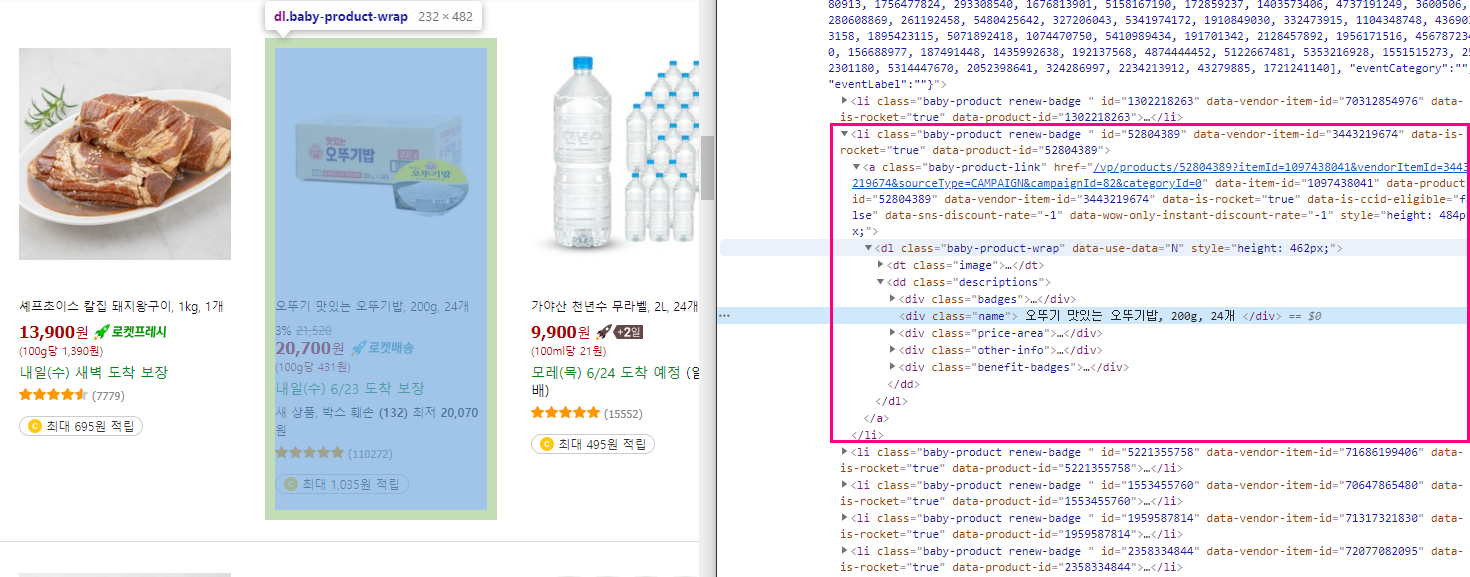
개발자도구를 켜서 상품의 정보가 어떤 태그에 있는지 확인해본 결과 <li>태그인 것을 확인할 수 있다.
<li>태그 아래 <div class="name">태그에 우리가 원하는 상품제목 정보가 들어있다. 이 부분까지 왔다면, 텍스트를 가져오면 되는 것이다.
코드를 이어서 작성하면 다음과 같다.
titles = soup.select('#productList > li')
number = 0
for title in titles:
number = number + 1
product_title = title.select_one('a > dl > dd > div.name').text
product_title = re.sub('\n','', product_title)
product_title = product_title.lstrip()
print('[' + str(number) + ']', product_title)
titles변수에 상품 정보가 들어있는 <li>태그들을 담는다.
select는 find_all과 비슷한 역할을 하는 함수이다. 이번시간에는 select를 이용해 정보를 가져왔다.
※ 참고 : find에서는 .get_text()를 이용해 텍스트를 가져왔다. 하지만, select_one을 사용할 경우, .text만 붙이면 된다.

soup.select('#productList > li') : id가 'productList'인 태그 아래 있는 <li>를 모두 가져온다는 의미이다.
number변수는 상품 개수를 파악하기 위한 것이므로 굳이 사용하지 않아도 된다.
for문을 통해 titles의 정보를 하나씩 확인하며, <div class="name">의 텍스트 정보를 가져오면 된다.
정규 표현식(re.sub)을 통해 개행을 없애주었다. (그래야 출력 결과가 깔끔하게 나오니까.)

쿠팡 파트너스를 하다보면, 상품제목, 정보, 가격, 리뷰개수 등을 빠르게 얻고 싶은 상황이 생긴다. 그럴 때 BeautifulSoup을 이용해 원하는 정보를 스크래핑 해보자! 이전보다 훨씬 더 빠르게 작업할 수 있을 것이다.
'Information' 카테고리의 다른 글
| 쿠팡파트너스 링크 우회 리디렉션 하는 방법(Feat.블로거) (0) | 2021.06.27 |
|---|---|
| 네이버블로그 쿠팡파트너스 저품질 피하기 (0) | 2021.06.26 |
| [Python] 네이버웹툰 크롤링 - 제목, 링크주소 가져오기 (0) | 2021.05.29 |
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 3 (0) | 2021.05.28 |
| [Python] BeautifulSoup을 이용한 네이버 블로그 크롤링 - 2 (0) | 2021.05.23 |



